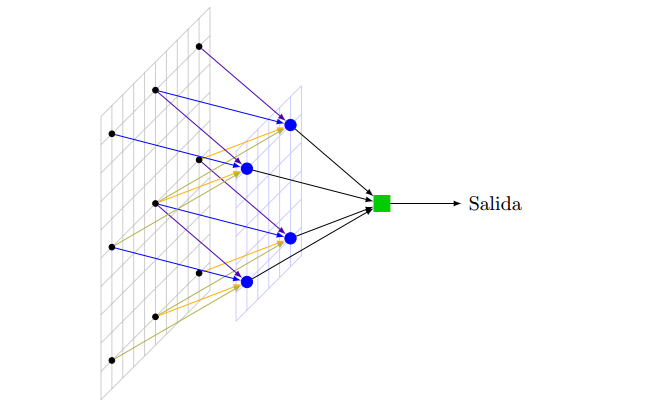
Estoy asistiendo a un curso de redes neuronales (matemática, nada de hardware) y el primer ejercicio es hacer funcionar un perceptrón simple (sin capas ocultas) para hacer un OCR (Reconocedor Optico de Caracteres).
Es un tipo de red neuronal que se dice asistida, porque se debe entrenar con relaciones de entrada-salida conocidas.
Les paso el enunciado (en el TP1_2014.pdf) y una implementación mía en Matlab (en el PCO1-c.zip) para un entrenamiento con 5 letras (A,B,C,D,E) y un conjunto de pruebas de 5 letras (las mismas pero con ruido).
Cada letra se arma con un arreglo de 5 pixels de ancho por otros 5 de alto, que se leen desde un archivo "dataset.m". Los arreglos se completan con un -1 al final para considerar los umbrales de activación de la red.
El entrenamiento consiste en calcular los factores de peso para cada entrada.
La neurona se entrena ejecutando con Matlab el script "ps_ent.m", rutina que, en cada pasada (o época):
1.- calcula los factores de peso para todas las muestras,
2.- calcula el error para todas las muestras,
3.- corrige los factores de peso para reducir el error total.
Esto lo repite hasta que el error de cada pasada sea menor que un determinado valor.
El programa pide entrar un coeficiente "llamado velocidad de aprendizaje", lo que permite ajustar algo la precisión y la cantidad de pasadas que se calculan.
Como en mi caso los "pesos" iniciales son al azar, cada vez se obtiene una solución diferente.
Al entrenar construye los bmp de cada letra, muestra la curva de aprendizaje (el error en función de las pasadas),

y el mapa de pesos en colores.

En una segunda etapa, para usar la red se ejecuta el el script "ps_uso.m".
El programa pide entrar el numero de ejemplo a probar con la red y el resultado es un nro binario de 10 bits escrito de atrás para adelante. Con las primeras 5 muestras no debería fallar, y con las 5 finales debería dar diferente según cuanto ruido uno le agrege a las muestras. Yo le puse dos o tres pixels cambiados.

No es nada del otro mundo, pero está bueno para empezar a experimentar y perderle el miedo al tema. Luego uno lo puede complicar todo lo que quiera.
El paso siguiente es poner algo como esto en una FPGA, y ya tenemos un pequeño cerebro electrónico, al menos para hacer cosas simples como reconocer caracteres.
No es chiste, creo que esto sería más simple que construir como alguien dijo antes una madeja de FPGAs que se auto configuren.