- Dado el tiempo minimo entre muestras de 25ns, y usando 100 pixels por division, tengo 2.5us / div como base de tiempos minima. Usando el algoritmo de interpolacion, empiezo a bajar esa base de tiempos. Si intercalo solo 1 sample calculado entre 2 reales, tengo 1.25us / div, pero cuando intercalo 3 samples calculados entre 2 reales, tengo 625ns/div y esos numeros no me gustan mucho. Quiero hacer cuentas para ver cuantos samples tengo que intercalar para hacer, digamos, en vez de 625ns/div: 500ns/div, 200ns/div, etc. (numeros mas redondos)
Bueno, pues este tema es muy interesante que lo propongas, porque gracias a que tienes polinomios interpoladores, puedes poner la base de tiempo arbitraria que necesites. Al tener la onda formada por una combinación de funciones continuas, puedes evaluar cada tramo de la función en el valor que necesites, no necesariamente una partición entera del intervalo original. Pongamos un ejemplo:
Si intecalas 4 samples entre 2 reales, tendrás una base de 500ns/div, ya que creas 5 segmentos por lo que partes un segmento de 2500ns/div entre 5. Esto equivale a ir recorriendo las X en pasos de [0 0,2 0,4 0,6 0,8 1] (los puntos 0 y 1 son reales, el resto son interpolados). Si te has dado cuenta, lo que hacemos es dividir la escala nueva por la escala vieja para obtener el paso necesario para pasar de un punto interpolado al siguiente, es decir, tenemos 500ns/2500ns=0,2. Ahora, si en lugar de 500ns queremos una escala de 1000, pues hacemos lo mismo, 1000ns/2500ns=0,4. Ahora los pasos para dibujar serán [0 0,4 0,8 1,2 1,6 2], donde 0 y 2 son puntos reales y los demás puntos interpolados.
¿Pero qué ha pasado con el punto 1?, pues que al quedarse entre medias no se imprime en pantalla, pero ya se imprimen los valores cercanos los puntos que están alrededor, es decir 0,8 y 1,2, por lo que la onda sigue fielmente representada en pantalla. De todas formas la función de interpolación sólo funciona en el intervalo 0 a 1, por lo que tenemos que partir el cálculo de los puntos interpolados [0,4 0,8 1,2 1,6] en 2 partes: La primera Y0 e Y1 serán el punto 0, y el 1, y los puntos a calcular serán 0,4 y 0,8. Y la segunda Y0 será ahora el punto 1 y Y1 el punto 2, y los puntos a calcular serán 0,2 (1,2-1) y 0,6 (1,6-1). Parece un poco lío, pero de forma algorítmica se resuelve simple y elegántemente con un bucle que vaya dibujando los pixeles en pantalla (o los guarde en un vector de gráfica para luego imprimirlos).
De hecho el incremento de cada paso no tiene por qué ser un valor tan limpio, puede ser cualquier valor real, de manera que podemos hacer una opción para personalizar la base de tiempos a nuestro antojo, por ejemplo si el usuario requiere que la base de tiempo sea de 720ns, pues 720/2500 = 0,288, así la secuencia interpolada será [0 0,288 0,576 0,864 1,152 1,440 1,728 2,016 2,304...] (los cálculos serán de 0,288, 0,576, 0,864 sobre el intervalo 0...1, 0,152, 0,440 0,728, sobre el intervalo 1...2, 0,016, 0,304... sobre el intervalo 2...3 y así hasta completar los pixeles en pantalla.
Así podría definir el algoritmo en pseudo C de la siguiente manera:
Código:
double incremento=escalanueva/escalavieja,j=0,X=0;
for(int i=0;(i<MAX_PIXEL)&&(j<MAX_DATOS);i++) {
X=trunc(j); //X será la parte entera de J.
if (X==j) Dibujapunto(i,DATOS[X]); //si j es entero, dibuja Y0 en el punto DATOS[X];
else {
Y0=DATOS[X]; //Preparamos los coeficientes para pasarlos a la función
Y1=DATOS[X+1];
Y2=DATOS[X+2];
Y_1=DATOS[X-1];
X=j-X; //ahora X es la parte decimal, ya que X debe de ir entre 0 y 1.
Y_interpolado=splines(Y_1,Y0,Y1,Y2,X); //Evaluamos X en el polinomio interpolado.
Dibujapunto(i,Y_interpolado);
}
j+=incremento;
}
Una pregunta aparte: Como uso 896 samples por canal, a 100 pixels por division en una pantalla cubro 8.96 divisiones. Si yo quisiera hacer que el programa simplemente calcule los pixeles restantes para llegar a 1000 samples (o sea, las 10 divisiones normales de cualquier osci) esta funcion polinomica no me sirve verdad? Supongo que no debido a que necesita 2 samples para calcular los intermedios y cuando X > 895 ya no dispongo de mas samples. Se que podria hacerlo de alguna otra forma pero no lo tengo muy claro. Alguna sugerencia?
Lamentablemente, mientras interpolar da una buena idea de una función si esta no es una función muy irregular (por ejemplo una función fractal no es interpolable ya que es infinitamente discontinua), ya que el objetivo de interpolar es representar una curva suave, el calcular puntos fuera de un intervalo, lo que ya no es interpolar sino extrapolar, no es que sea dificil si no que la señal que obtienes extrapolando no es que no sea real (que lo es, al igual que los puntos interpolados dentro de un intervalo), es que ni siquiera lo parece ya que cuanto más te alejas de los puntos utilizados para calcular el valor irreal, más se desvía dicho valor de algo parecido a la función original. Por ejemplo puedes interpolar sin problemas una senoidal de 100 puntos, pero cuando vas a calcular los 50 puntos siguientes de fuera de la senoidal, te encuentras cualquier cosa menos la senoidal.
Pues sobre ideas, una que no me gusta mucho, y otra que me gusta más. La que no me gusta mucho es suponer que al ser la señal periódica, reproducir una parte del principio a continuación del final. No me gusta esto porque cuando la señal no es periódica estás engañando a quien ve la captura. Por ejemplo, imagina que estamos viendo un tren de bits modulados. Cuando terminara esa zona de pantalla con los datos reales, lo siguiente sería o bien extrapolación o duplicado del principio, lo que confundiría a la hora de analizar los datos, ya que por ejemplo si los datos son 1 0 0 1 0 1 0 0 pero en pantalla solo se han capturado la representación modulada de 1 0 0 1, veríamos esto 1 0 0 1 1 0... lo cual no es la señal original y puede dar muchos dolores de cabeza a quien esté analizándola.
La idea que se me pasa por la cabeza es hacer la ventana más pequeña de manera que en lugar de que te falten datos te sobren, por ejemplo: haces una división cada 50 pixeles y cubres 500 muestras en 10 divisiones. El resto de samples los usas como buffer de pantalla, de manera que el usuario pueda recorrer la ventana mediante flechas o botones desde 0 hasta 895 samples (por ejemplo podría situar la ventana entre el sample 165 y el 665). ¿Que la ventana se queda muy pequeña?, no hay problema, haces zoom x2, división cada 100 pixeles e interpolas 1 punto entre muestras para tener en total 1792, y haces la ventana de 1000 puntos (a recorrer entre 0 y 1791).
Esta solución es la más elegante y la que creo que implementan muchísimos osciloscopios.
Otra: Una vez perfeccionado el soft en la parte de interpolacion, planeo que el mismo me de datos utiles, como ser, una etiqueta que me diga de que frecuencia es la señal. Se me ocurrio que, mientras voy recorriendo los samples, calcular el valor minimo y maximo: Luego, cuando tengo esos datos, contar cuantos samples pasan desde un minimo pasando por un maximo y hasta un minimo de nuevo. Ahi podria calcular la frecuencia. Tendria que poner algo con un error de un cierto % debido a que esos minimos y maximos bien pueden ser picos en la señal y no la señal en si. No me gusta... es muy "fuerza bruta". ¿Hay algo mejor para hacer esto?
Vamos a ver. Parámetros interesantes para calcular cuando tenemos una onda:
-Valor Máximo
-Valor Mínimo
-Frequencia principal
-Nivel de continua
-Valor eficaz (RMS).
Con el tema de la frecuencia, tienes razón, el que comentas es un método poco fiable para poder medir la frecuencia, ya que el hecho de que hayan máximos y mínimos locales (crestas y valles) no significa que la frecuencia sea la inversa de la distancia entre cresta y cresta. Podrías estar calculando sin querer la frecuencia de un armónico (la señal de normal será la suma de varios armónicos que hacen que la onda vaya subiendo y bajando muchas veces más que la frecuencia original).
Para tener una indicación fiable no hay más remedio que usar una transformación de la serie temporal de los datos a una serie frecuencial, es decir calcular la FFT. Aunque tienes 896 puntos, puedes calcular la FFT óptima de 1024 puntos ya que añadir los puntos de valor 0 que faltan no varía las componentes frecuenciales de la FFT.
La FFT te va a calcular puntos en el plano complejo, cada punto tiene una parte real y otra imaginaria, pero a ti lo que te interesa es conocer el módulo de cada frecuencia (amplitud). Dado un número complejo, a+bi, su módulo es sqrt(a^2+b^2). Ya de entrada te digo que una vez calculada la FFT, la componente primera, es la de frecuencia 0, entonces esa primera componente es el valor medio, o la componente en continua, de la señal muestreada. Buscando un valor que nos interesa nos hemos encontrado con otro valor que también nos interesa.
Ahora, si tenemos 1024 puntos, y hacemos una FFT, la primera frecuencia es la componente que se repite cada 0 samples(la continua). La segunda es la que se repite cada FFT/2, la tercera se repite cada FFT/4, la cuarta cada 3/4 FFT, y así, hasta la componente 512 que es la frecuencia que se repite cada 2 samples (la frecuencia de nyquist). Del 513 al 1024 es la misma FFT que de 1 a 512, pero reflejada en orden descendente, por lo que no hace falta que te fijes en ese tramo... Así sabiendo la frecuencia de la FFT que te interesa, sabes cual es la frecuencia de la señal que necesitas.
La frecuencia principal de una onda, quitando su valor de continua FFT[0], es la frecuencia de la componente de la FFT que tenga mayor amplitud. Así que para saber la frecuencia de tu señal, recorres las amplitudes de las 512 frecuencias de la FFT, y te quedas con la frecuencia de mayor amplitud. Así sabrás cada cuantos samples la onda se repite.
El problema es que la FFT te va a dar una aproximación digital de la frecuencia, nunca una frecuencia que no sea racional (porque usando series discretas sólo podemos tener frecuencias racionales, es decir, frecuencias que se puedan expresar en una fracción de la frecuencia de muestreo). Cuando tienes muchos puntos, esta frecuencia digital será bastante próxima a la frecuencia real de la señal, (por ejemplo, pongamos que la frecuencia real es 3.141593 MHz, y al calcular la FFT de la señal muestreada, nos da una frecuencia de 3.142857 MHz..., que es el resultado de que la razón de la señal con respecto a la frecuencia de muestreo sea de 22/7. Entonces pongamos que cada 7 puntos la señal se repite en el análisis digital, pero en realidad se debería de ir repitiendo cada 7.0028174 puntos. Tienes ahí una pequeña fracción de 0,0028174 que te va a introducir un error en el cálculo de la frecuencia (esto es sólo una estimación, el error real entre el muestreo y la frecuencia real va creciendo conforme la onda va acercándose a la frecuencia de muestreo).
Entonces podemos ayudarnos con las funciones polinómicas de interpolación para aproximar el punto X exacto donde la onda se repite. Ponemos que una onda vale 5 en el punto 0, y la FFT nos dice que su frecuencia principal es de 16 samples. Pues en el sample 16 deberíamos esperar encontrar un 5, pero nos encontramos con un 6. En el sample anterior, el 15, tenemos un 4,5. Entonces tenemos un intervalo, desde X=15,Y=4,5 hasta X=16,Y=6, y entre un valor de ,llamemosla Xu, de entre 15 a 16, debe de haber un valor de Xu donde Yu sea 5. Pongamos que podemos construir dentro de ese intervalo un polinomio interpolador que llamaremos P(X). Podemos construir una función F(X)=P(X)-Yu, de forma que F(X) sea 0 para el valor de Xu esperado. Entonces debemos aproximar X a Xu para conseguir que F(Xu)=0. Esto lo podemos hacer bien resolviendo directamente las soluciones del polinomio interpolador de tercer grado (un peaso de fórmula increiblemente grande, pero se puede hacer), o bien numéricamente en varios pasos con el método de la bisección, el de la secante, o el de newton (el de la bisección da buen resultado ya que tenemos un intervalo definido). Entonces encontramos una Xu=15,37 por ejemplo, la cual F(15,37)=0, por lo tanto P(15,37)=5= valor del sample 0. Entonces 15,37 samples será una mejor aproximación de la frecuencia que el valor de 16 samples que nos había dado la FFT.
Sobre los valores máximos y mínimos: Pues puedes recorrer todos los valores de la muestra e ir investigando si el valor actual es mayor o menor que el máximo y mínimo provisionales, hasta finalizar el vector de muestras. El problema de nuevo lo tenemos en que estamos midiendo unos valores máximos y mínimos sobre muestras discretas, y sin embargo disponemos de funciones continuas donde podemos calcular el máximo y el mínimo de cualquier tramo de la función, por lo que encontrar la cresta y el valle en esas funciones nos sería muy útil ya que casi nunca va a coincidir el valor de la muestra con el valor de cresta o valle de la onda.
Bueno, pues resulta que para encontrar la cresta y el valle de un polinomio de tercer grado (el punto donde la pendiente de subida y bajada se hace 0), lo que hay que hacer es derivarlo e igualar la derivada a 0, de manera que obtenemos una ecuación sencilla de segundo grado que podemos resolver teniendo dos soluciones Xa y Xb, mediante la conocidisima fórmula de ecuaciones de segundo grado, pero adaptada a los coeficientes de la derivada de nuestro polinomio interpolador:
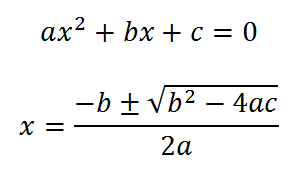
Esas soluciones existirán siempre (excepto cuando lo que multiplica a X^2 es cero, porque entonces tenemos solución única que será X=-c/b. Pero tanto Xa como Xb tienen que encontrarse dentro del intervalo 0 y 1 para que nos sirvan, de forma que si Xa y Xb vale por ejemplo -1,34 y 2,37, pues en el intervalo 0 y 1 no tiene un punto de valle ni de cresta, entonces para saber dentro de ese intervalo cual es el máximo o el mínimo, sólo hay que ver el valor en el punto 0 y el 1 y ver cual es mayor que el otro. En definitiva, para saber el máximo y el mínimo de un intervalo 0...1, tenemos considerar 4 puntos y ver cual es el mayor y cual es el menor dentro de ese intervalo, es decir X=0, X=Xa, X=Xb, X=1. Y luego ir recorriendo el vector hasta encontrar el valor máximo absoluto y el mínimo.
El programa lo he implementado y probado en Octave:
Código:
function [xmax ymax xmin ymin] = maxminsplines(samples)
Y_1=samples(length(samples));
xmax=0;
ymax=0;
xmin=0;
ymin=0;
for i=1:(length(samples)-1)
Y0=samples(i);
Y1=samples(i+1);
if (i==length(samples)-1)
Y2=samples(1);
else
Y2=samples(i+2);
end
S=Y2+Y0-2*Y1;
T=Y1+Y_1-2*Y0;
A=(S-T)/2;
B=(2*T-S)/2;
C=(Y1-Y_1)/2;
D=Y0;
if A==0
X1=-C/(2*B);
X2=X1;
else
X1=(-2*B+sqrt(4*B^2-12*A*C))/(6*A);
X2=(-2*B-sqrt(4*B^2-12*A*C))/(6*A);
end
Y1=A*X1^3+B*X1^2+C*X1+D;
Y2=A*X2^3+B*X2^2+C*X2+D;
if X1>0 && X1<1 && imag(X1)==0
if Y1 >ymax
ymax=Y1;
xmax=i+X1;
end
if Y1 <ymin
ymin=Y1;
xmin=i+X1;
end
end
if X2>0 && X2<1 && imag(X2)==0
if Y2 >ymax
ymax=Y2;
xmax=i+X2;
end
if Y2 <ymin
ymin=Y2;
xmin=i+X2;
end
end
if D>ymax
ymax=D;
xmax=i;
end
if (A+B+C+D)>ymax
ymax=A+B+C+D;
xmax=i+1;
end
if D<ymin
ymin=D;
xmin=i;
end
if (A+B+C+D)<ymin
ymin=A+B+C+D;
xmin=i+1;
end
Y_1=Y0;
end
return
end
Como ves, ahora ya no hace falta introducir en el programa el número de puntos a interpolar, ya que lo que se calcula es el valor máximo y mínimo absoluto en un X que no tiene que ser una partición fracional del intervalo 0..1 sino que se encontrará en cualquier parte de ese intervalo. Ahora tampoco se devuelve el vector de interpolación sino los valores X e Y máximos y mínimos.
Ejemplo, tenemos estos puntos representados en la siguiente gráfica:

Y para comparar con la función interpolada N=25 que sería esta:

Ahora usamos la función maxminsplines para encontrar los X e Y máximos y mínimos de los polinomios interpoladores de los samples y tenemos este resultado:
Código:
octave-3.6.4.exe:49> [xmax ymax xmin ymin]=maxminsplines(Y)
xmax = 12.574
ymax = 0.99667
xmin = 17.603
ymin = -0.99680
octave-3.6.4.exe:50> [y x]=max(Y)
y = 0.96350
x = 13
octave-3.6.4.exe:51> [y x]=min(Y)
y = -0.96781
x = 18
Es decir, sin interpolar, el máximo lo da en el sample 13, con valor 0,96350, y el mínimo en el sample 18 con el valor -0,96781. Usando los máximos y mínimos encontrados por interpolación, encontramos un máximo en el sample 12,574 con valor 0,99667 y un mínimo en el sample 17,603 con valor -0.99680. Como ves, uno se acerca al sample 13 y el otro al 18. Los máximos y mínimos se acercan más al máximo y mínimo teóricos de una senoidal que es 1 y -1.
Bueno, pues sobre el valor eficaz de la señal ya hablaré más adelante y te iré explicando qué es y cómo se calcula (es que se me ha hecho ya tarde). Por lo pronto te enseño una función que he hecho otra vez en matlab para calcular el valor eficaz de las funciones interpoladas de una secuencia de samples:
Código:
function salida = RMSsplines(samples)
Y_1=samples(length(samples));
intparcial=0;
for i=1:(length(samples)-1)
Y0=samples(i);
Y1=samples(i+1);
if (i==length(samples)-1)
Y2=samples(1);
else
Y2=samples(i+2);
end
S=Y2+Y0-2*Y1;
T=Y1+Y_1-2*Y0;
A=(S-T)/2;
B=(2*T-S)/2;
C=(Y1-Y_1)/2;
D=Y0;
intparcial=intparcial+A^2/7+(A*B+2*B*D+C^2)/3+(2*A*C+B^2)/5+(A*D+B*C)/2+C*D+D^2;
Y_1=Y0;
end
salida=sqrt(intparcial/length(samples));
return
end
Esta función es una función que devuelve un valor que es el valor RMS REAL, no aproximado, de la secuencia de polinomios interpoladores. Cuanto más parecidos sean los polinomios interpoladores a la onda real, más se parecerá el valor RMS real de los polinomios al valor RMS de la onda que aproximan.
Saludos.












") El osciloscopio lo hice mayormente directo en PCB wizard, usando un poco el proteus para simular algunas condiciones. (entrada analogica, trigger,etc pero la parte de captura digital la hice "en la cabeza")
El osciloscopio lo hice mayormente directo en PCB wizard, usando un poco el proteus para simular algunas condiciones. (entrada analogica, trigger,etc pero la parte de captura digital la hice "en la cabeza")







