Compactación y codificación de fonemas
Ya sea para almacenamiento optimizado, o con vistas a reconocimiento automático.
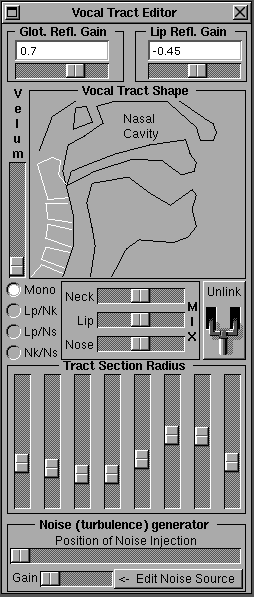
Un método de compresión del habla se basa en un modelo físico simplificado del tracto
vocal (desde las "cuerdas vocales" hasta los labios), modelado como una sucesión de
"tramos de caño" desadaptados en impedancia acústica.
La desadaptación proviene de las diferentes "secciones" del tracto vocal, y genera
múltiples reflexiones internas. Resultado de estas reflexiones, a la salida se obtiene un
único fonema.
Aquí se puede ver un aparato que realiza ese proceso físicamente, con un tracto vocal
hecho en silicona y controlado por unas pinzas que le daban la sección a cada tramo.
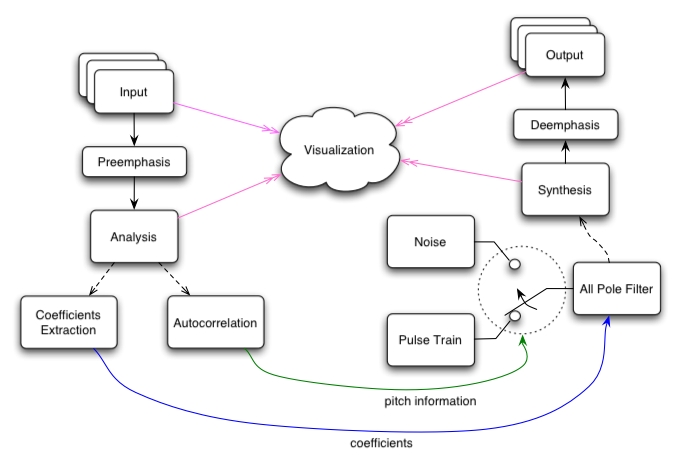
Así, el tracto se puede representar mediante el conjunto de coeficientes que describen
el sistema. Estos son los coeficientes de predicción lineal o LPC.
Los LPC representan las sucesivas desadaptaciones acústicas entre un "tramo de caño"
los vecinos.
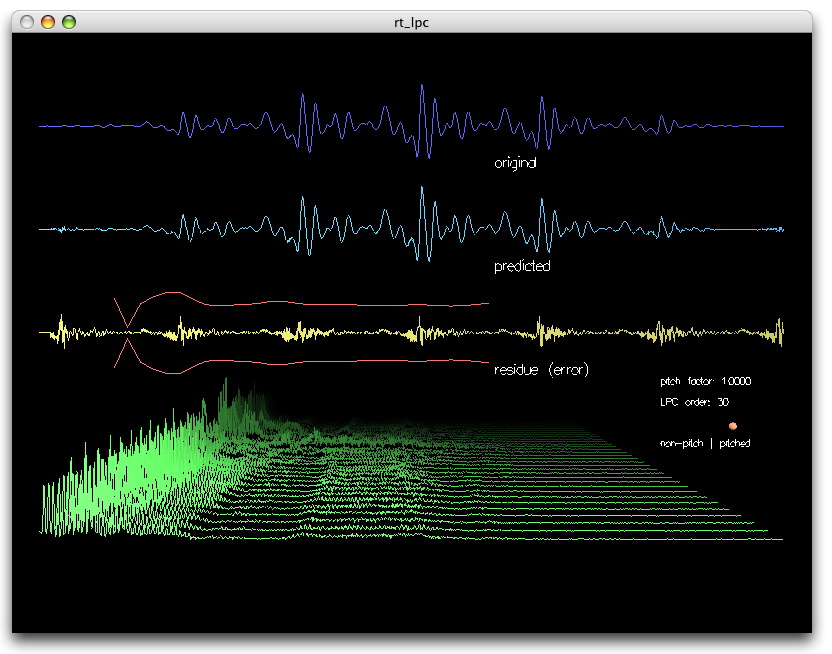
Para el cálculo de los LPC se suele emplear el método de Durbin-Watson basado en la
autocorrelación de la señal.
Entonces los fonemas se pueden "codificar" mediante los LPC del tracto vocal (apenas
14 coeficientes por fonema). Y como a cada fonema le corresponde un único conjunto
LPC es posible usar este método para almacenar el habla humana en forma compactada.
Para darse una idea:
Supongamos querer almacenar el fonema "la", de 1 segundo de duración, muestreado
con un pic a 10.000 muestras por segundo (10 kSps).
Almacenando todas las muestras digitalizadas se deberían guardar 10.000 datos (10 kB).
El método LPC permite describir el mismo fonema con solo 14 coeficientes ...
lográndose una compresión de casi 1000 veces !!!
Nota: El valor óptimo que surge del análisis de errores es 14. Con mucho menos de 14
coeficientes se tiene una resolución pobre, con mucho más de 14 el sistema de ecuaciones
se vuelve inestable.
Hasta ahí sería una ventaje enorme.
Pero además esto permitiría pensar en identificar fonemas, haciendo el cálculo de los LPC
a tiempo real, y luego comparando con LPC previamente almacenados en una biblioteca.
Ver También:
Reconocimiento de palabras usando LPC y DTW para control de robot
El promedio del espectro del habla. Fundamentos y aplicaciones clínicas.
Inteligibilidad del Habla (1) - Inteligibilidad del Habla (2)
Reconocimiento del Habla - Estado del avance del tema en el mundo (Estado del arte)
Ya sea para almacenamiento optimizado, o con vistas a reconocimiento automático.
Un método de compresión del habla se basa en un modelo físico simplificado del tracto
vocal (desde las "cuerdas vocales" hasta los labios), modelado como una sucesión de
"tramos de caño" desadaptados en impedancia acústica.
La desadaptación proviene de las diferentes "secciones" del tracto vocal, y genera
múltiples reflexiones internas. Resultado de estas reflexiones, a la salida se obtiene un
único fonema.
Aquí se puede ver un aparato que realiza ese proceso físicamente, con un tracto vocal
hecho en silicona y controlado por unas pinzas que le daban la sección a cada tramo.
Así, el tracto se puede representar mediante el conjunto de coeficientes que describen
el sistema. Estos son los coeficientes de predicción lineal o LPC.
Los LPC representan las sucesivas desadaptaciones acústicas entre un "tramo de caño"
los vecinos.
Para el cálculo de los LPC se suele emplear el método de Durbin-Watson basado en la
autocorrelación de la señal.
Entonces los fonemas se pueden "codificar" mediante los LPC del tracto vocal (apenas
14 coeficientes por fonema). Y como a cada fonema le corresponde un único conjunto
LPC es posible usar este método para almacenar el habla humana en forma compactada.
Para darse una idea:
Supongamos querer almacenar el fonema "la", de 1 segundo de duración, muestreado
con un pic a 10.000 muestras por segundo (10 kSps).
Almacenando todas las muestras digitalizadas se deberían guardar 10.000 datos (10 kB).
El método LPC permite describir el mismo fonema con solo 14 coeficientes ...
lográndose una compresión de casi 1000 veces !!!
Nota: El valor óptimo que surge del análisis de errores es 14. Con mucho menos de 14
coeficientes se tiene una resolución pobre, con mucho más de 14 el sistema de ecuaciones
se vuelve inestable.
Hasta ahí sería una ventaje enorme.
Pero además esto permitiría pensar en identificar fonemas, haciendo el cálculo de los LPC
a tiempo real, y luego comparando con LPC previamente almacenados en una biblioteca.
Ver También:
Reconocimiento de palabras usando LPC y DTW para control de robot
El promedio del espectro del habla. Fundamentos y aplicaciones clínicas.
Inteligibilidad del Habla (1) - Inteligibilidad del Habla (2)
Reconocimiento del Habla - Estado del avance del tema en el mundo (Estado del arte)
Última edición: